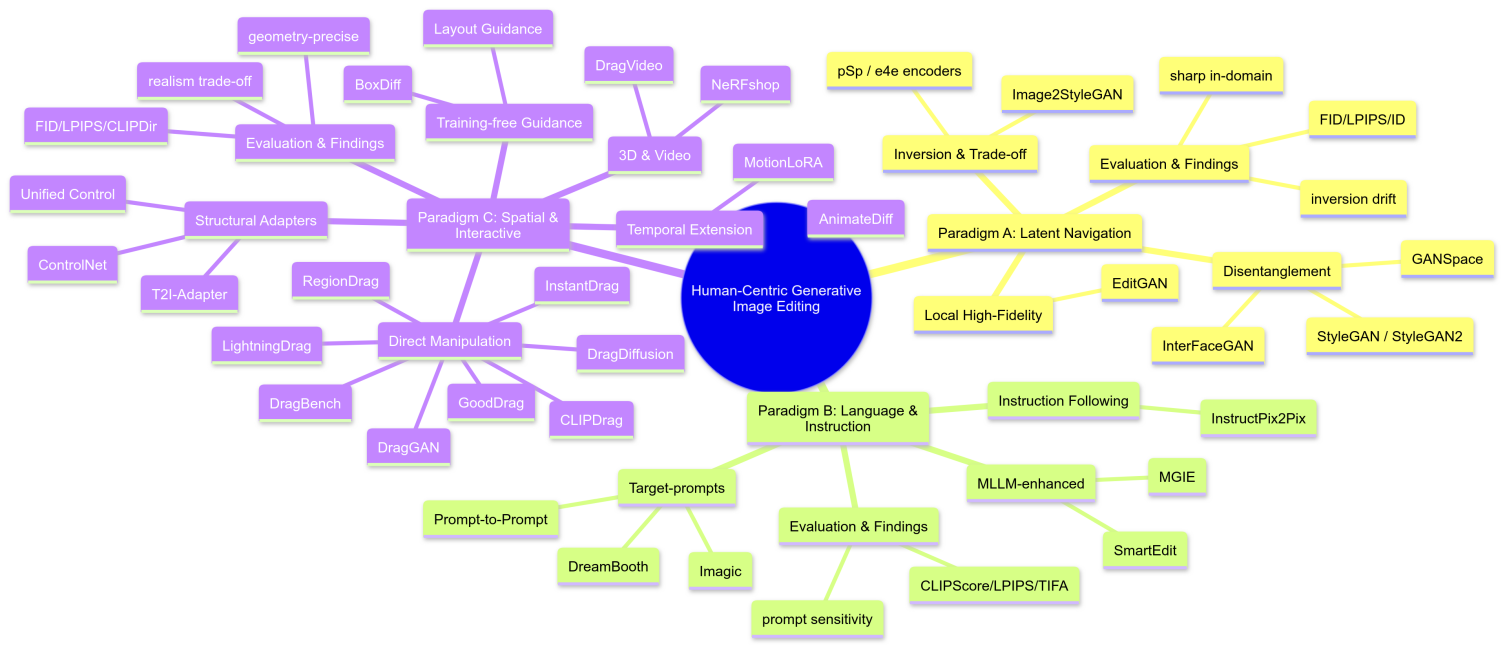
Over the past ten years, the image editing field has experienced a paradigm evolution driven by pixel-wise control, such as Adobe Photoshop, to generative models. With the rise of Generative Adversarial Networks(GANs) and diffusion models, it is now possible to control images through a higher-level semantic understanding. This core vision aims to bridge the gap between human intention and model performance. To address this challenge, the research has shifted from improving generative quality to editing methods, which puts "human-in-the-loop" at the core. The evolution of control reflects the changes in user communities: from code-based abstract latent space manipulation used by early researchers, to the later natural language-based text-to-image image editing (such as InstructPix2Pix), and finally developed to the direct drag-and-drop interaction represented by DragGAN for creators without background mechanisms. The alternative from technical mechanisms. "model-centered" to "user-centered" means the democratization of content creation tools, implying more focus on human-computer interaction principles in future research. To clearly outline the development of this field, this review categorizes existing methods into three paradigms based on the discrepancy in human control modalities: latent spatial navigation, language-guided manipulation, and direct spatial and structural control. This paper's unique contribution is that, systematically analyzes and reviews groundbreaking research that has been conducted since 2018, based on GANs and diffusion models, focusing on "human-control". This paper reveals the inner revolutionary logic of different types of methods, aiming to provide a unique perspective for understanding the future development trend of controllable generative technology.