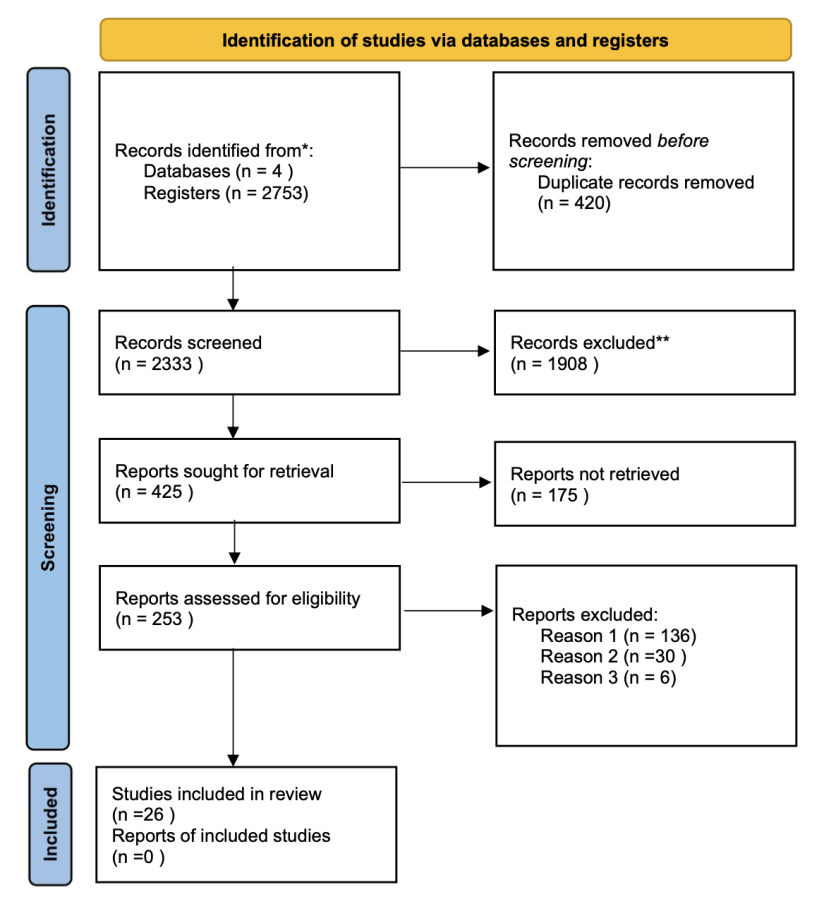
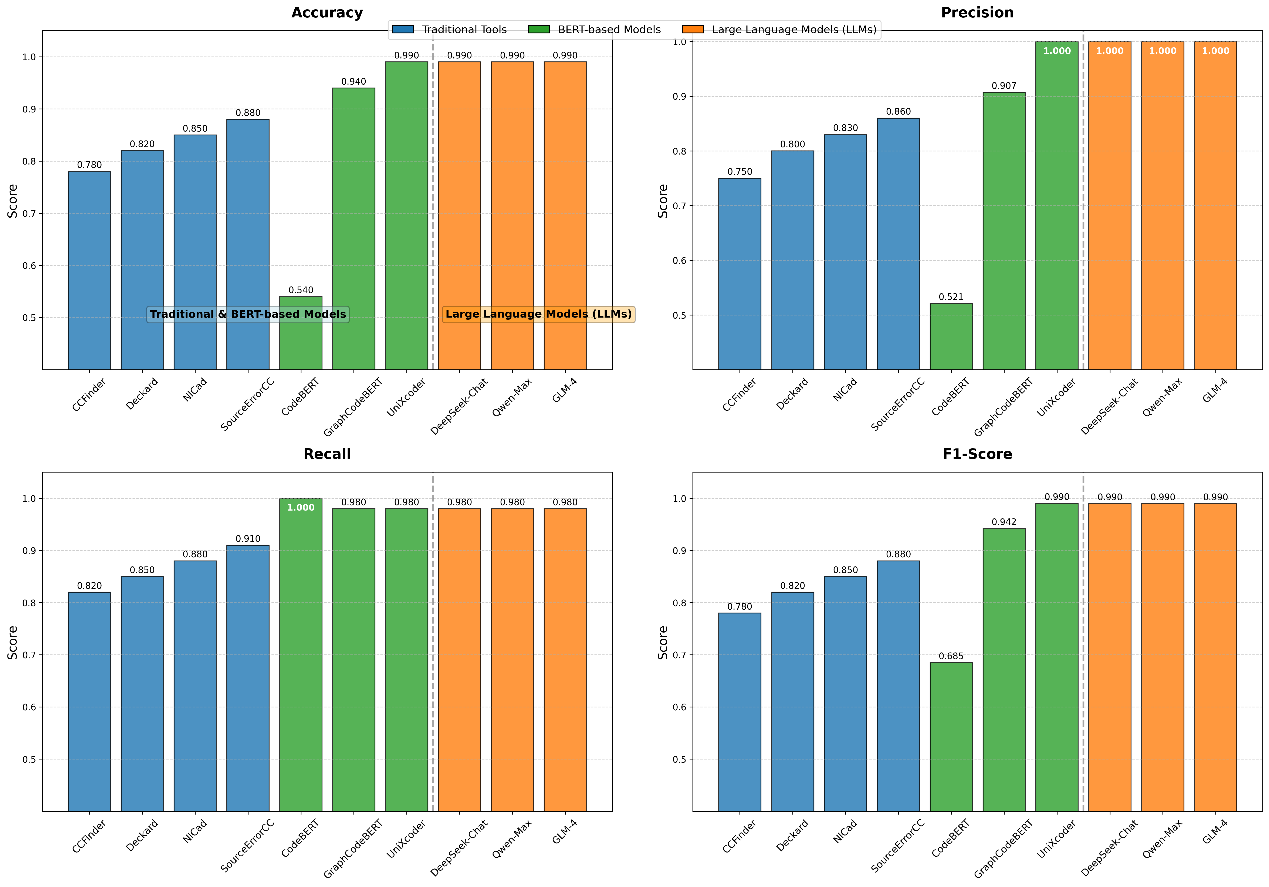
With the widespread deployment of machine learning models in high-stakes decision-making contexts, their inherent opacity—often termed the "black-box" problem—has raised significant concerns regarding interpretability and reliability. This paper presents a systematic and comprehensive literature review examining the convergence of interpretable machine learning and statistical inference. This paper synthesizes foundational concepts, methodological frameworks, theoretical advancements, and practical applications to elucidate how statistical tools can validate, enhance, and formalize machine learning explanations. This review critically analyzes widely adopted techniques such as SHAP and LIME, and explores their integration with statistical inference tools, including hypothesis testing, confidence intervals, Bayesian methods, and causal inference frameworks. The analysis reveals that integrated approaches significantly improve explanation credibility, regulatory compliance, and decision transparency in critical domains, including healthcare diagnostics, financial risk management, and algorithmic governance. However, persistent challenges remain in theoretical consistency, computational efficiency, evaluation standardization, and human-centered design. This paper concludes by proposing a structured research agenda focusing on unified theoretical frameworks, efficient algorithmic implementations, domain-specific evaluation standards, and interdisciplinary collaboration strategies to advance the responsible development and deployment of explainable AI systems.
Research Article
Open Access