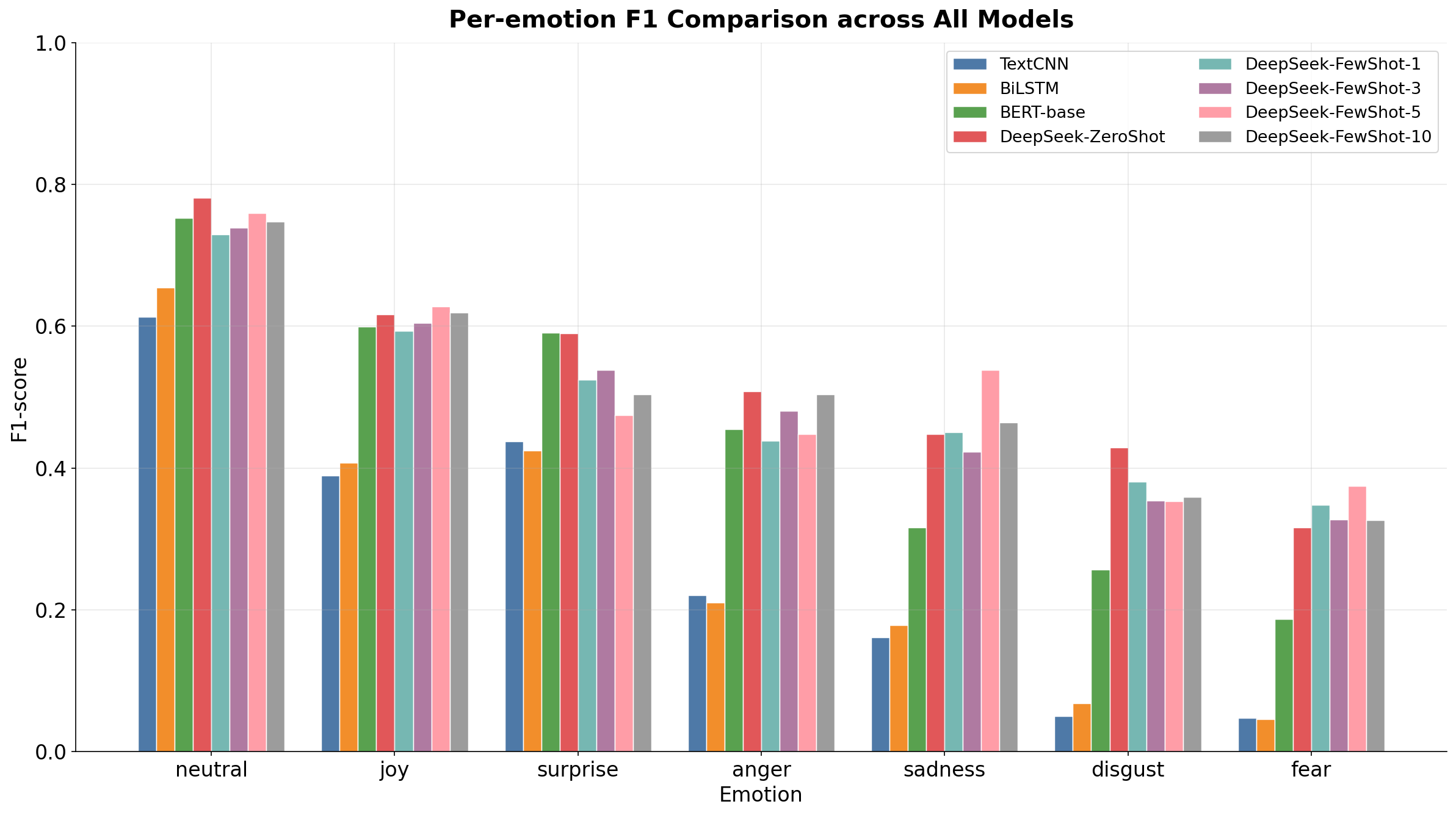
Emotion recognition (ER) poses a complex multi-class classification challenge, further complicated by significant class imbalances. In natural dialogue corpora, dominant emotions like neutral are prevalent, while minority emotions such as disgust and fear are notably scarce. This imbalance results in models consistently underperforming on less frequent categories. This paper investigates template-guided prompting as a method to improve long-tail emotion recognition using large language models (LLMs). We employ a unified evaluation framework on the MELD dataset to compare various methods: supervised baselines (TextCNN, BiLSTM), a fine-tuned pre-trained model (BERT-base), and training-free LLM inference (DeepSeek) using three structured prompt templates in both zero-shot and few-shot scenarios (K=1, 3, 5, 10). Our findings demonstrate that template-guided LLM prompting achieves the highest overall performance (Acc=0.6573, Macro-F1=0.5268) and significantly enhances minority-class F1 scores compared to all supervised baselines, without requiring parameter updates. A detailed analysis of hard-sample errors shows that 16.9% of test instances are misclassified by all five models, with minority emotions having hard-sample rates up to 48%. This bias remains even with balanced downsampling (Pearson r=0.986) and is linked to a systematic prediction bias toward the neutral class. These results imply that the difficulties in long-tail ER arise from intrinsic semantic ambiguity rather than just data imbalance, and that structured prompting offers a practical and effective solution for achieving more balanced emotion recognition.