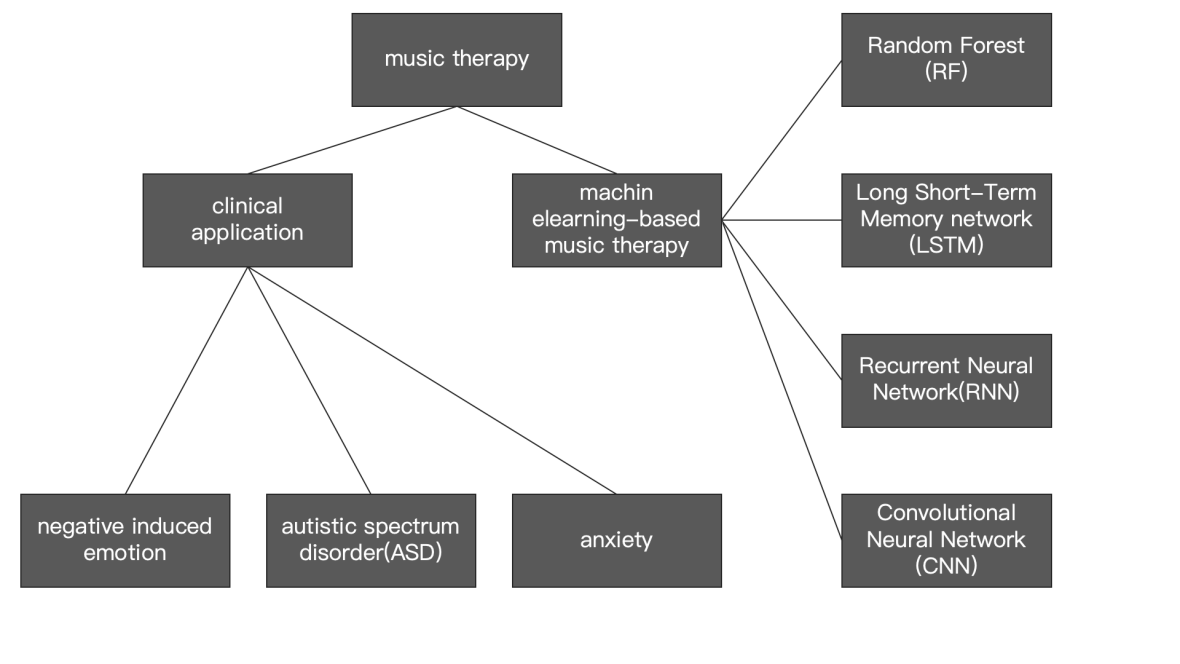
The advent of multimedia technology has precipitated a paradigm shift in the realm of human-computer interaction and affective computing, thus rendering multimodal emotion recognition a pivotal domain. However, the issue of modal absence, resulting from equipment failure or environmental interference in practical applications, significantly impacts the accuracy of emotion recognition. The objective of this paper is to analyse multimodal emotion recognition methods oriented to modal absence. The focus is on comparing and analysing the advantages and disadvantages of techniques such as generative class and joint representation class. Experimental findings demonstrate the efficacy of these methods in surpassing the conventional baseline on diverse datasets, including IEMOCAP, CMU-MOSI, and others. Notably, CIF-MMIN enhances the mean accuracy by 0.92% in missing conditions while concurrently reducing the UniMF parameter by 30%, thus preserving the SOTA performance. Key challenges currently being faced by researchers in the field of multimodal emotion recognition for modal absence include cross-modal dependencies and semantic consistency, model generalisation ability, and dynamic scene adaptation. These challenges may be addressed in the future through the development of a lightweight solution that does not require full-modal pre-training, and by combining comparative learning with generative modelling to enhance semantic fidelity. The present paper provides both theoretical support and practical guidance for the development of a highly robust and efficient emotion recognition system.
Research Article
Open Access