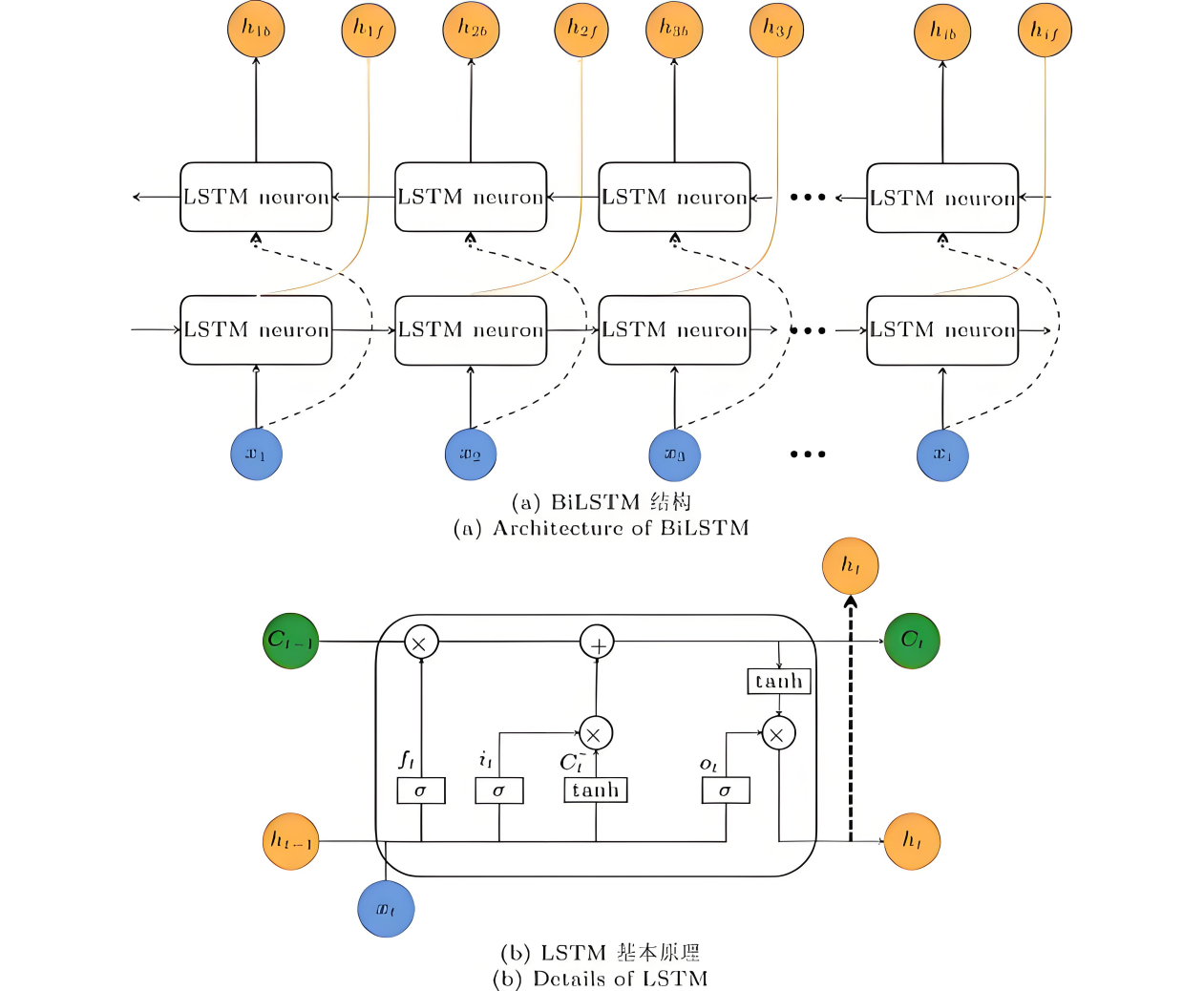
This study aims to improve the accuracy of animation style classification and provide more effective machine learning algorithm support for the intelligent retrieval, personalized recommendation, and intelligent development of creative assistance tools on animation content platforms. This paper innovatively proposes an optimization model (BiLSTM Transformer) that integrates bidirectional long short-term memory network (BiLSTM) and Transformer architecture to address the complex sequence features contained in animation data. In order to comprehensively evaluate the performance of the model, we conducted systematic comparative experiments with various representative models such as random forest, decision tree, XGBoost, CatBoost, and BP neural network. The experimental results show that the proposed BiLSTM Transformer model has achieved a significant breakthrough of 95.7% in classification accuracy, far exceeding the performance of the suboptimal model (91.8%), demonstrating a performance advantage of a discontinuous approach. Moreover, the model has consistently achieved over 95% accuracy, recall, and F1 score in key evaluation metrics, demonstrating its outstanding comprehensive performance and robustness. In contrast, the accuracy of all compared models is below 92% and shows a stepwise downward trend: the decision tree model (81.2%) has obvious overfitting problems; Random forest, as the best traditional method, still lags behind the new model by 3.9 percentage points in accuracy (91.8%); XGBoost and CatBoost are limited in their effectiveness due to the difficulty of fully learning the complex dependencies between sequences; BP neural network performs the weakest in nonlinear modeling ability due to the vanishing gradient problem. These comparative results fully verify that the BiLSTM Transformer model can effectively model and understand complex sequence patterns and style features in animation data by combining the powerful capturing ability of BiLSTM for long-distance contextual information and the focusing advantage of Transformer's self attention mechanism on key features. As a result, it has achieved excellent predictive performance in animation style classification tasks, providing strong technical support for related intelligent applications.