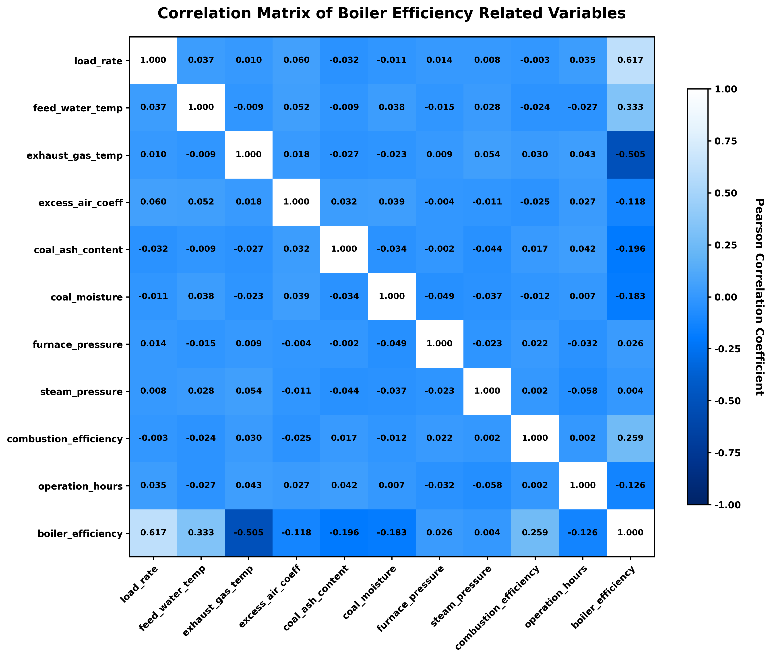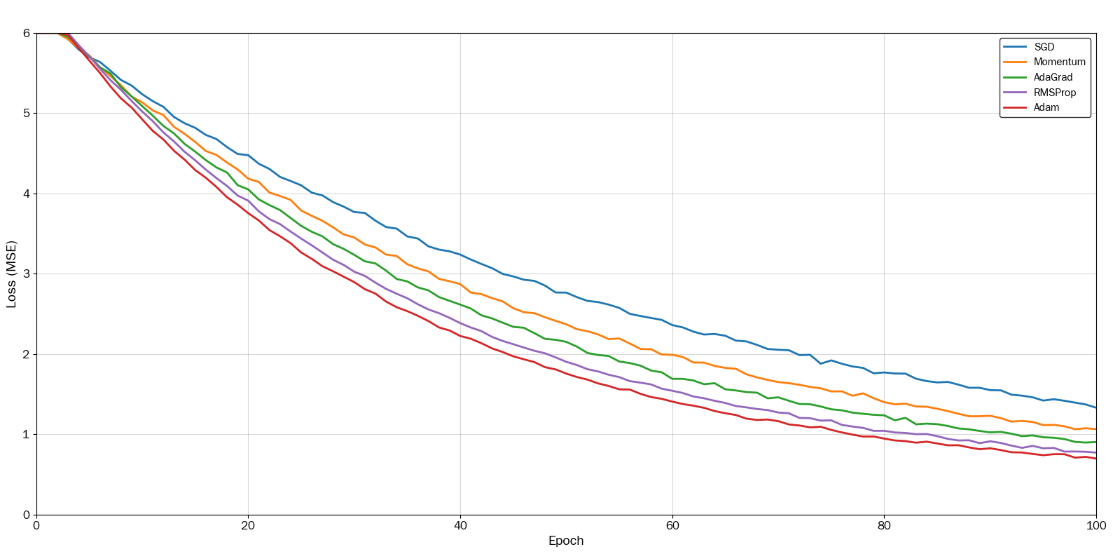
This paper conducts two comparative experiments. One uses the Software Developer Salary Prediction Dataset, whose target variable is continuous and has a wide value range. The other uses the Red Wine Quality Dataset, whose target variable is quasi-discrete with a narrow value range and whose features are sparse. Five mainstream optimizers are selected for these two experiments: Stochastic Gradient Descent (SGD), Momentum, Adaptive Gradient Algorithm (AdaGrad), Root Mean Square Propagation (RMSProp), and Adaptive Moment Estimation (Adam). To ensure fair experimental implementation, parameters are unified in the experiments. The same weight initialization method is adopted for all optimizers. For datasets, min-max normalization is applied to salary data and Z-score normalization to wine quality data. In addition, a fixed random seed (42) is used throughout. No learning rate scheduling or early stopping is applied during the training of all optimizers, so that their convergence properties can be fully observed. Experimental results are recorded with high precision: two decimal places for salary prediction results and five decimal places for wine quality prediction results to ensure optimal visualization. Experimental results show that adaptive optimizers outperform basic optimizers, but the choice of the best optimizer still depends on the specific task. Finally, guidance is provided for dataset types in practical applications.