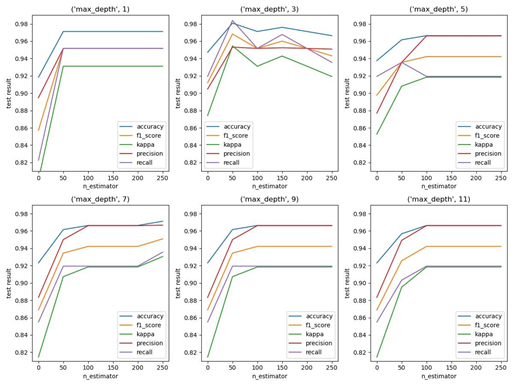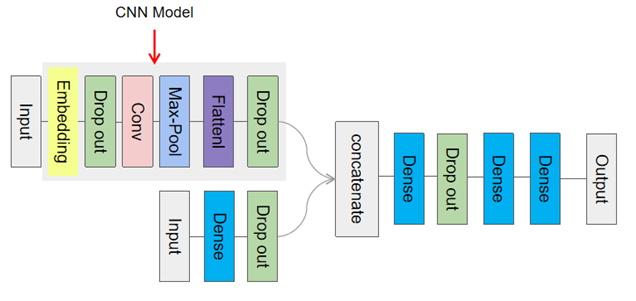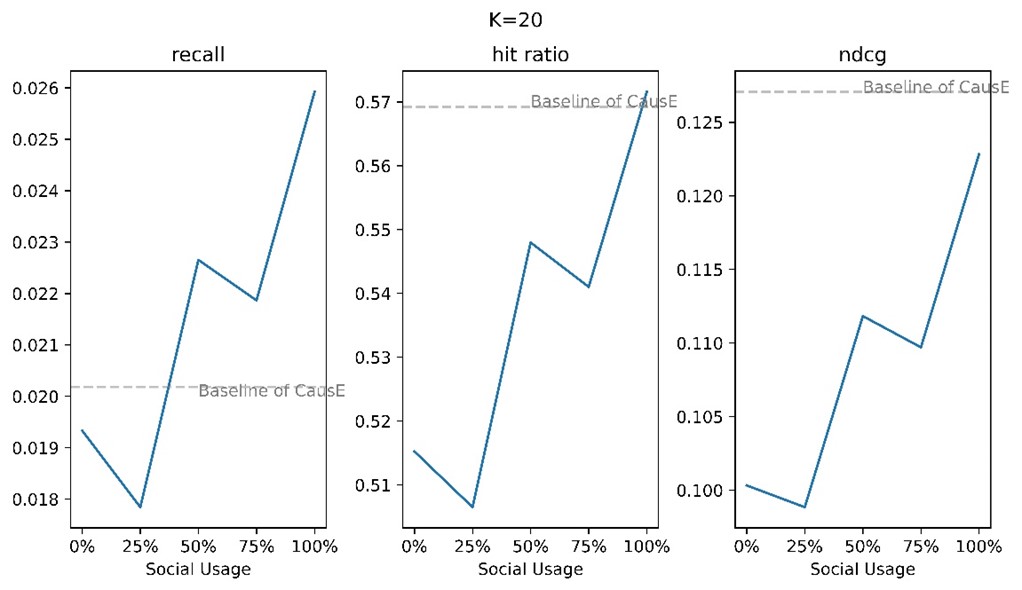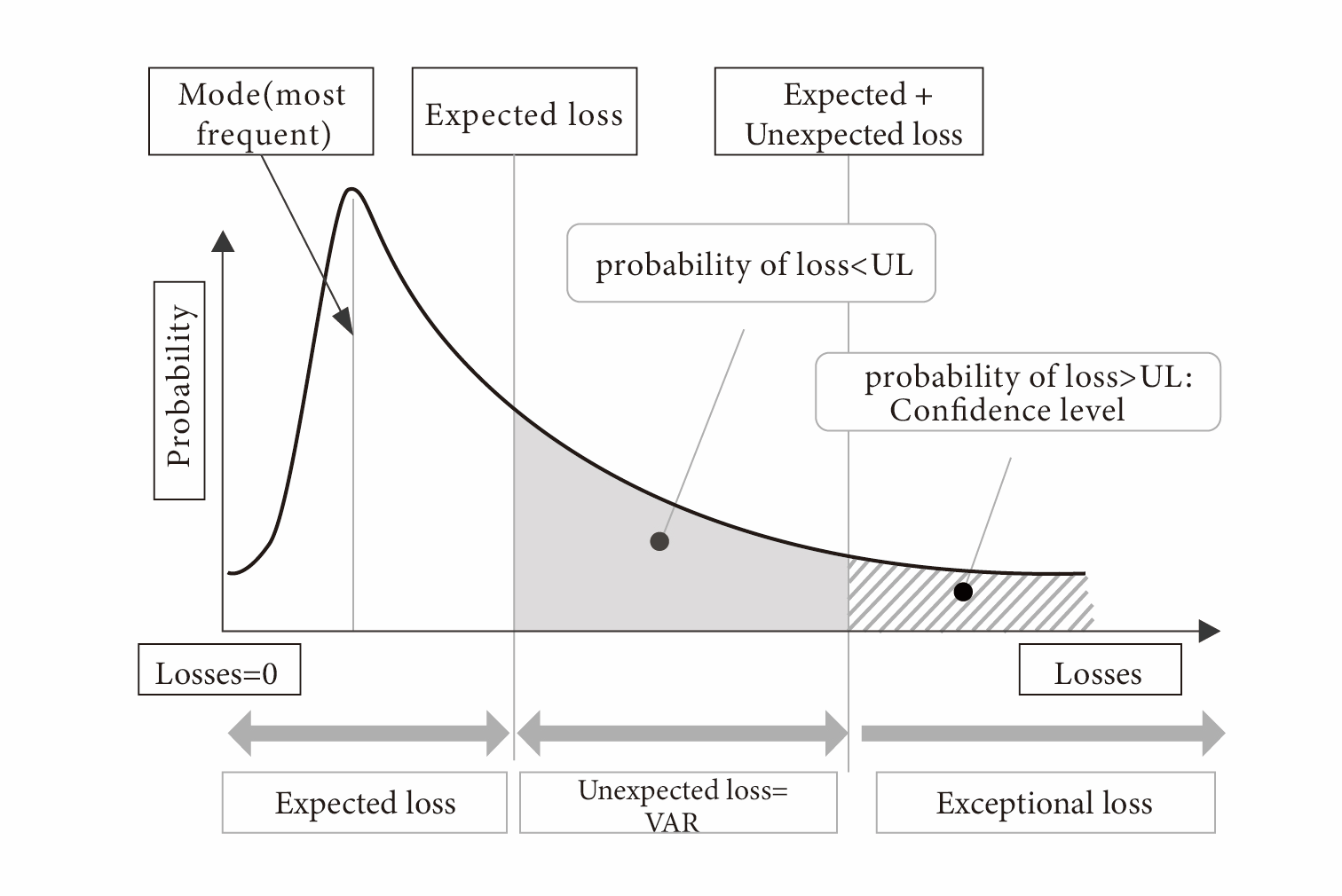
Amidst the escalating complexities that define the contemporary financial market and the rapid proliferation of information, traditional methods of formulating investment decisions confront increasingly formidable challenges. In response to these intricate dynamics, the realm of financial data mining has emerged as a prominent avenue of scholarly investigation within the investment domain. This paper's fundamental objective is to conduct a comprehensive retrospective analysis of the diverse applications of financial data mining in the context of investment decision-making.This scholarly pursuit entails a meticulous synthesis of existing academic inquiries, concurrently proposing potential avenues for future advancements in this field. By undertaking this academic endeavor, the paper strives to make substantive contributions to the refinement of methodologies essential for adeptly navigating the multifaceted landscape of modern investments. As the financial landscape continues to evolve, this study aspires to offer insights that not only enhance the efficacy of investment strategies but also foster a deeper understanding of the intricate interplay between data mining techniques and decision-making processes. Through the synthesis of empirical findings and theoretical perspectives, this paper seeks to underscore the pertinence of leveraging data-driven approaches in investment practices, thereby promoting a more informed and sophisticated investment landscape.