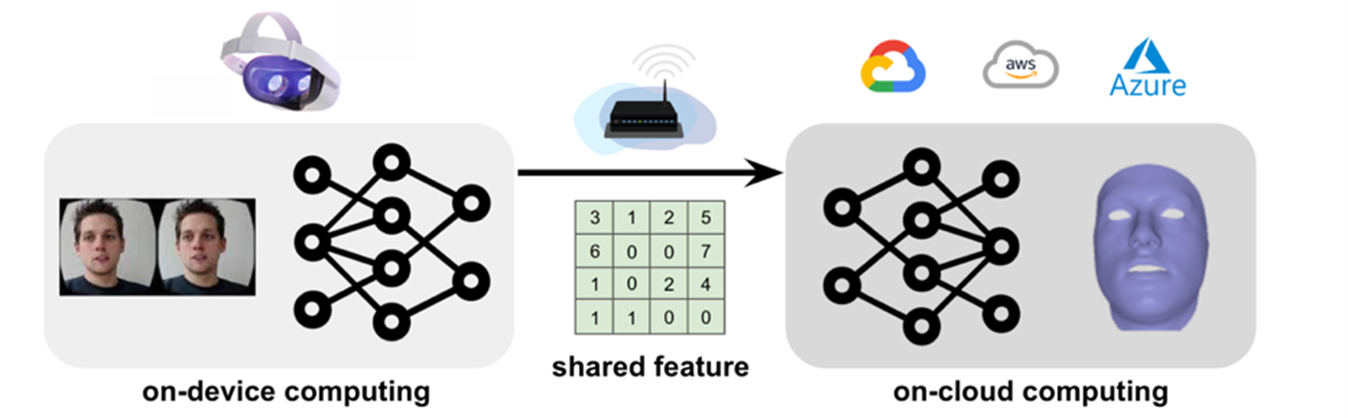
To decrease workload on lightweight devices, this project accelerates the computation of Convolution Neural Networks (CNNs) and preserves accuracy through modifying the CNNs’ training process. First, this research implements distributed computing to optimally divide the network workload onto both devices and the cloud. To reduce communication latency between devices and the cloud, this research introduces feature pruning by setting elements in the communicated feature to 0. However, naively pruning the feature causes a significant accuracy drop. To compensate for this limitation, this research applies pruning-aware training to preserve the CNNs’ task performance. This research evaluates the proposed methods on multiple datasets and CNN models, like VGG-11 and ResNet-18 with PyTorch. Empirical results demonstrate that the methods can reduce the computational latency by 50-75% with a negligible 1% accuracy loss. Specifically, this research first identifies the system bottleneck by comparing on-device, on-cloud, and communication latencies (on-device: 14.8%, on-cloud: 1.7%, communication: 83.5%). Then, this research compares multiple pruning strategies and observe the superiority of magnitude-based pruning. At 0.992 sparsity, magnitude-based pruning outperforms other strategies by 45% in accuracy. Finally, this research verifies the effectiveness of the proposed pruning-aware training method by comparing it with the baseline at various splitting points and networks. Pruning-aware training decreases the accuracy loss by up to 26% at 0.998 sparsity. In conclusion, even though distributed computing accelerates applications on lightweight devices, compressing the communication cost is crucial and challenging. This research proposed methods effectively reduce communication latency without sacrificing accuracy, conserving the effectiveness of CNN.