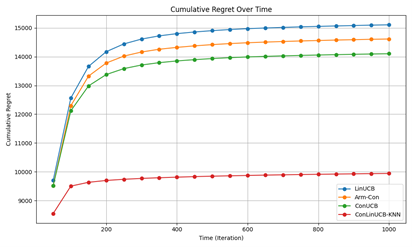
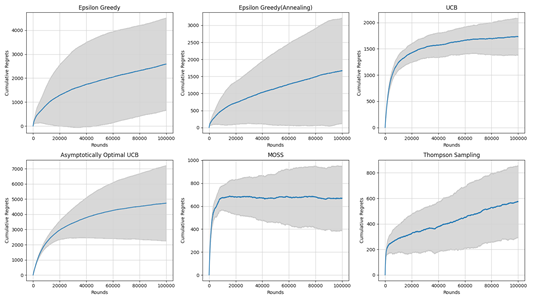
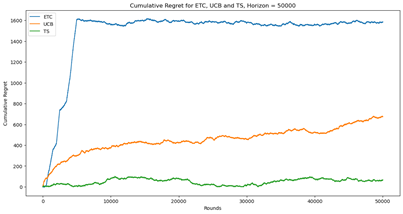
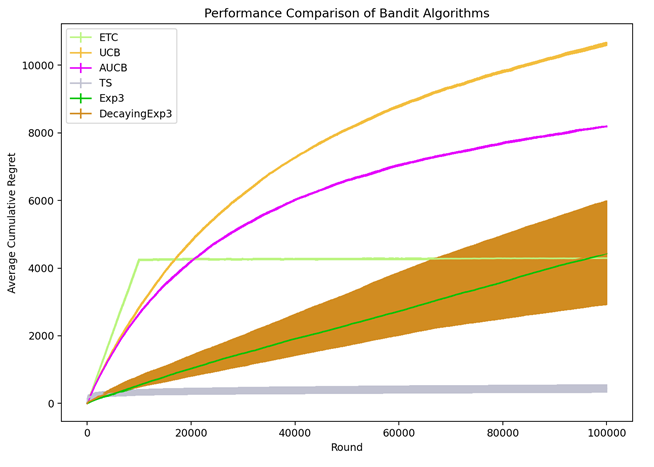
With the development of GPS positioning technology, a large amount of spatiotemporal trajectory data has been generated. Due to the complex structure of trajectory data, which has irregular spatial shapes and continuous temporal sequence attributes, querying massive trajectory data poses certain challenges. The pruning strategy of existing trajectory similarity query methods is not very effective. Even after pruning operations, there are still a large number of trajectories that need to undergo distance calculations to confirm whether they are similar trajectories. This paper proposes multiple local pruning optimization schemes, which maximally reduce the number of trajectories in the candidate set. Specifically, it starts with region pruning in the index space, eliminating index spaces with distances greater than the maximum similarity distance from the query trajectory. Then, it performs distance pruning between trajectories, removing trajectories that do not meet the distance conditions. Finally, it adds a termination condition: when the distance between the current index space and the query trajectory is greater than the maximum similarity distance and the number of trajectories in the result set is K, the loop is exited, and the query process ends. Tests on real datasets demonstrate that the KTSS method outperforms current algorithms of the same type.
Research Article
Open Access