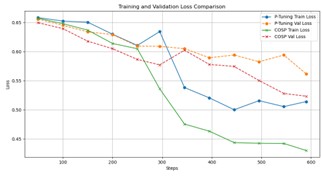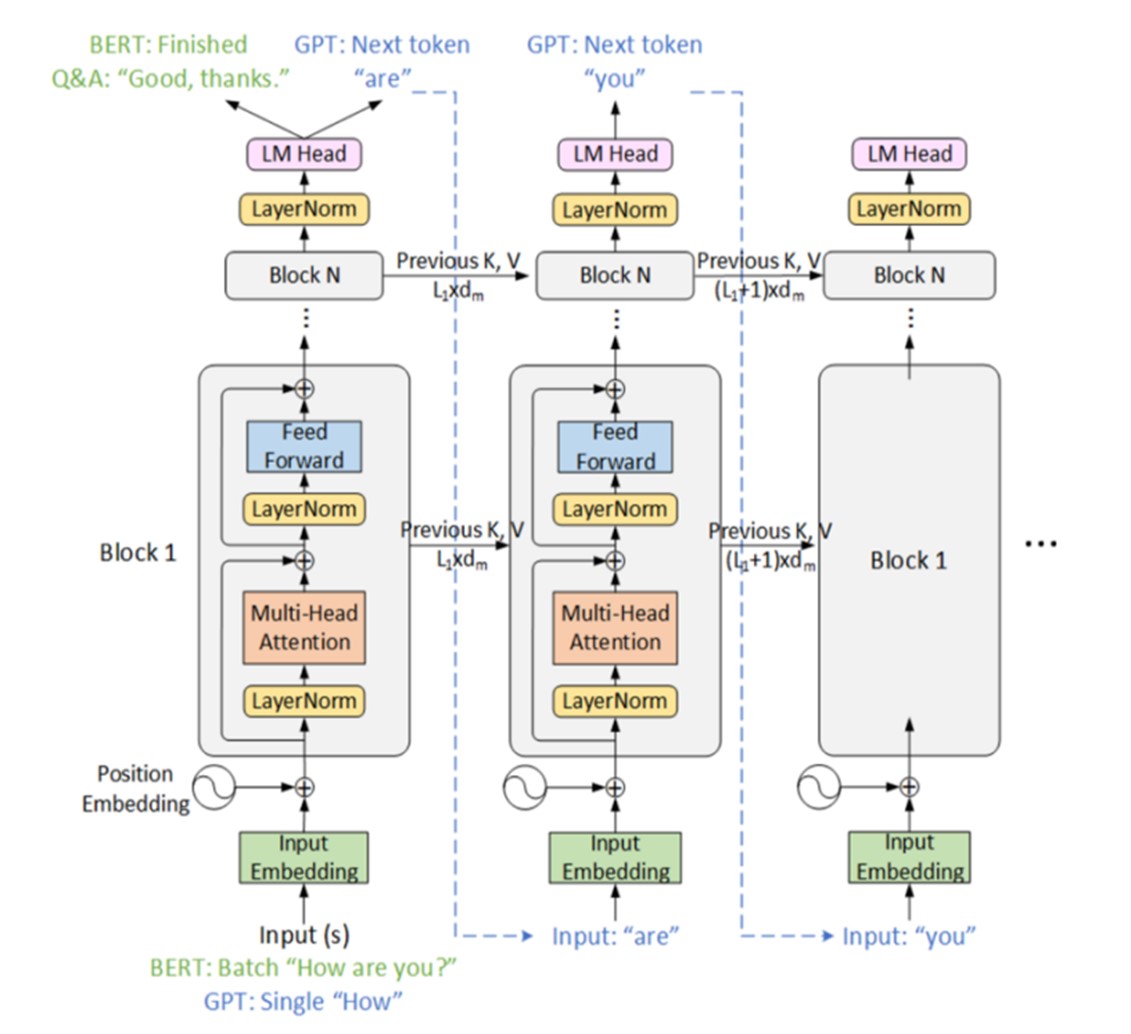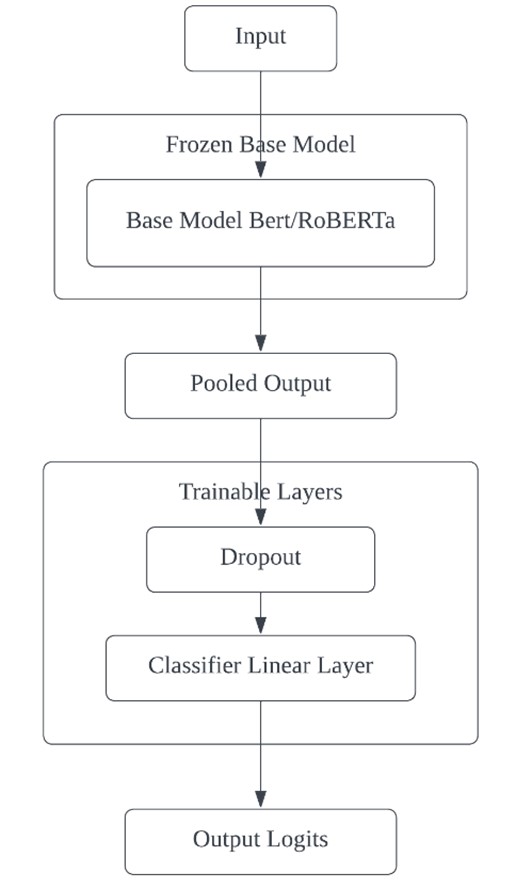
This paper presents an advanced approach to sarcasm detection in online discourse using state-of-the-art language models. The study systematically evolves Bidirectional Encoder Representations from Transformers (BERT) and Robustly Optimized BERT Pretraining Approach (RoBERTa) architectures from baseline to optimized versions, demonstrating significant improvements in sarcasm detection accuracy. Utilizing a balanced subset of 30,000 samples from a Reddit sarcasm dataset, the research implements gradual unfreezing, adaptive learning rates, and sophisticated regularization techniques. The final RoBERTa model achieves 76.80% accuracy, outperforming BERT and showing balanced precision and recall across sarcastic and non-sarcastic classes. The comparative analysis reveals interesting learning dynamics between BERT and RoBERTa, with RoBERTa demonstrating superior performance in later training stages. The study highlights the importance of architectural innovations and advanced training strategies in capturing the nuanced linguistic cues of sarcasm. While computational constraints limited the dataset size, the research provides valuable insights into model behavior and sets a foundation for future work. The paper concludes by discussing potential avenues for advancement, including scaling to larger datasets, exploring multi-modal approaches, and developing more interpretable models, ultimately contributing to the broader field of natural language understanding and affective computing.