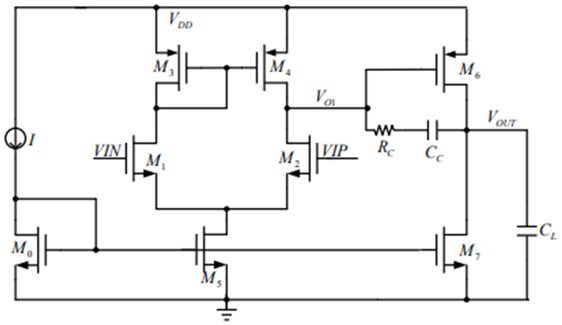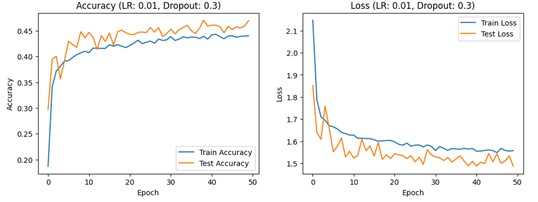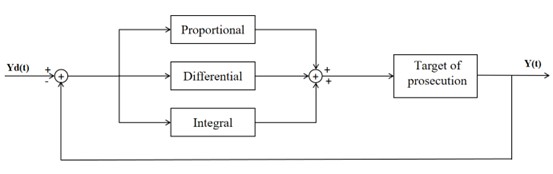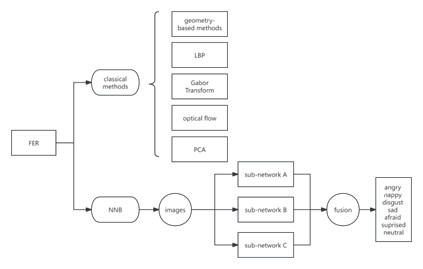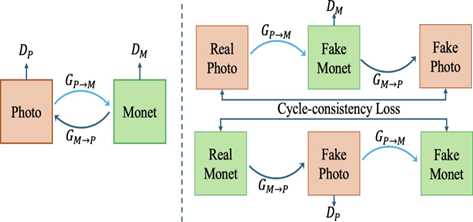
This project explores various approaches to style transfer, specifically focusing on transforming natural images into the iconic style of Claude Monet’s paintings. We explored three methods: CycleGAN-based, neural painting-based, and diffusion- based. CycleGAN enables style transfer between domains without paired training data, neural painting simulates the physical painting process, and diffusion models leverage a denoising process for high-quality results. To evaluate the effectiveness of these approaches, we conduct a survey assessing the aesthetic appeal, naturalness, and adherence to Monet’s style of the generated images. Our analysis provides insights into the strengths and limitations of each method and identifies areas for future improvement in reproducing Monet’s iconic style.