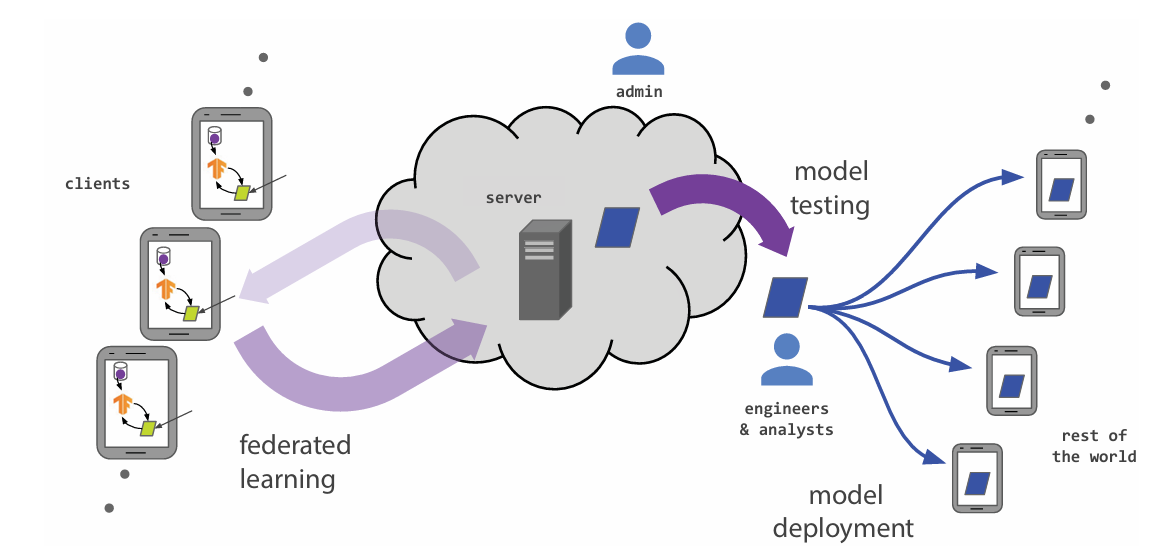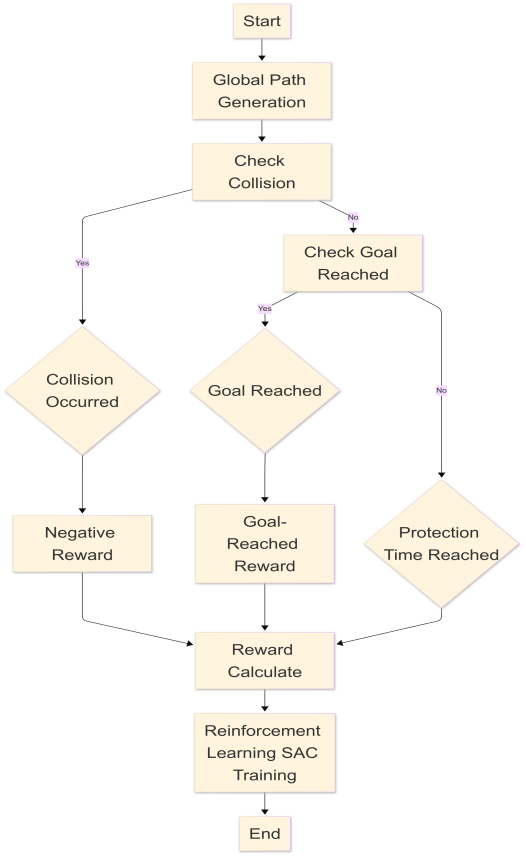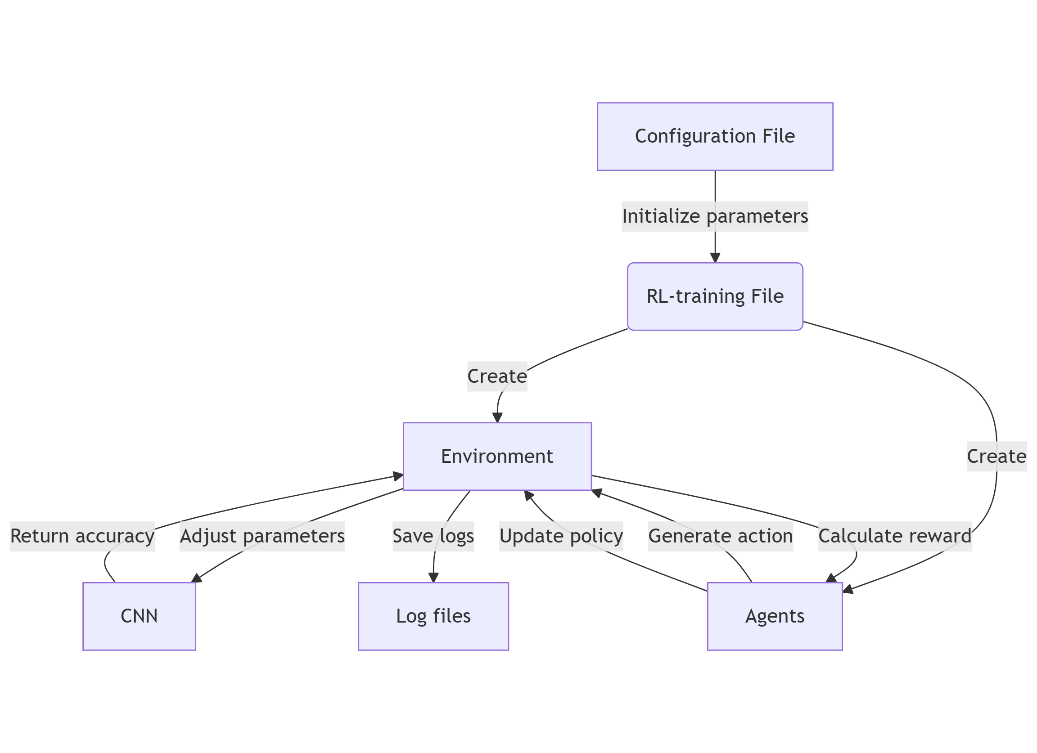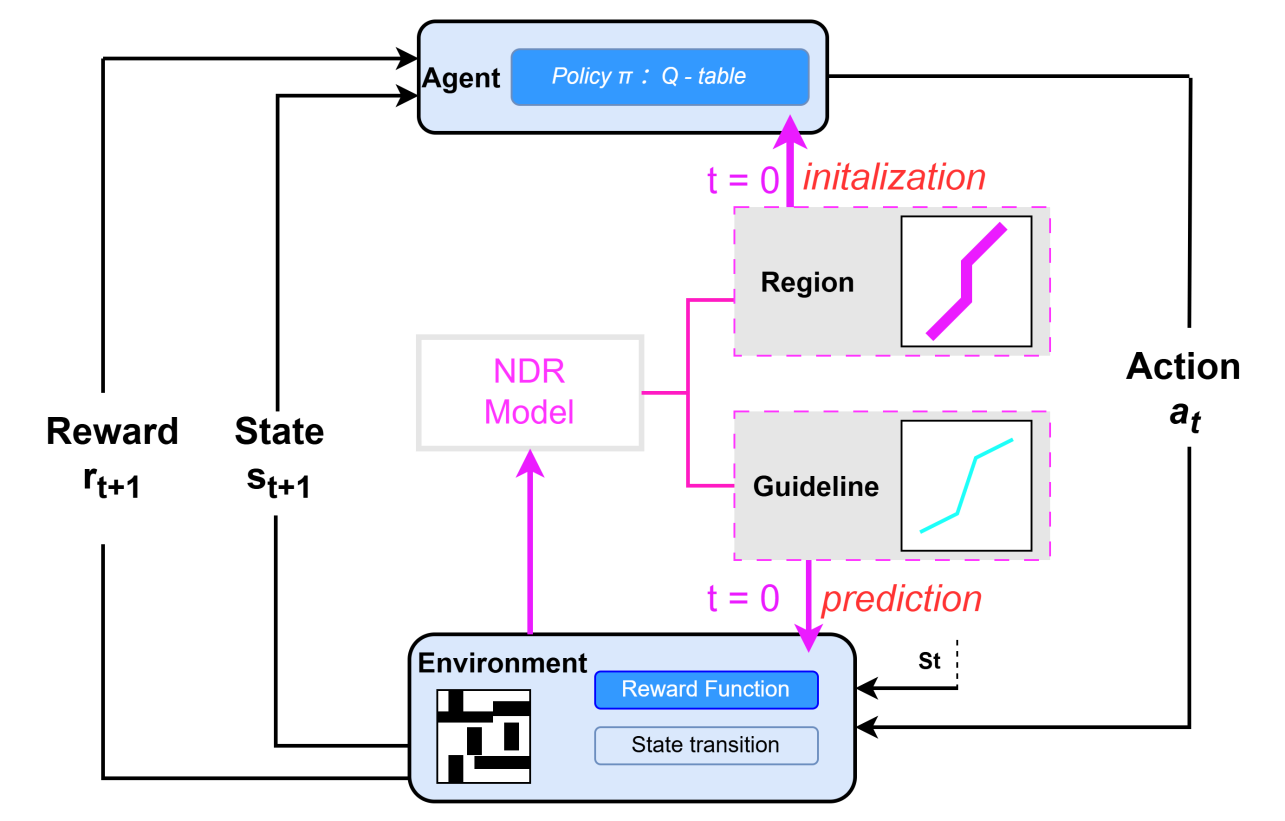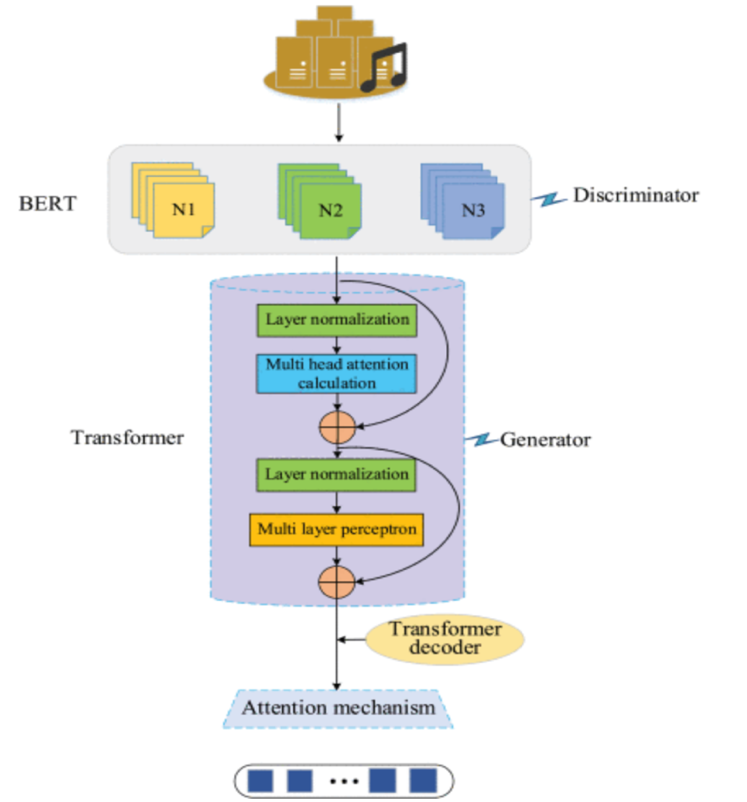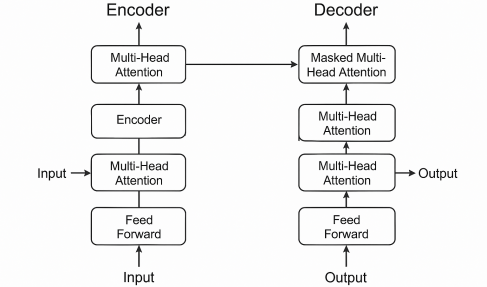
This paper systematically investigates the co-evolution of adaptive optimization algorithms and deep learning architectures, analyzing their synergistic mechanisms across convolutional networks, recurrent models, generative adversarial networks, and Transformers. The author highlights how adaptive strategies—such as gradient balancing, momentum acceleration, and variance normalization—address domain-specific challenges in computer vision, natural language processing, and multimodal tasks. A comparative analysis reveals performance trade-offs and architectural constraints, emphasizing the critical role of adaptive optimizers in large-scale distributed training and privacy-preserving scenarios. Emerging challenges in dynamic sparse activation, hardware heterogeneity, and multi-objective convergence are rigorously examined. The study concludes by advocating for unified theoretical frameworks that reconcile algorithmic adaptability with systemic scalability, proposing future directions in automated tuning, lightweight deployment, and cross-modal optimization to advance AI robustness and efficiency.