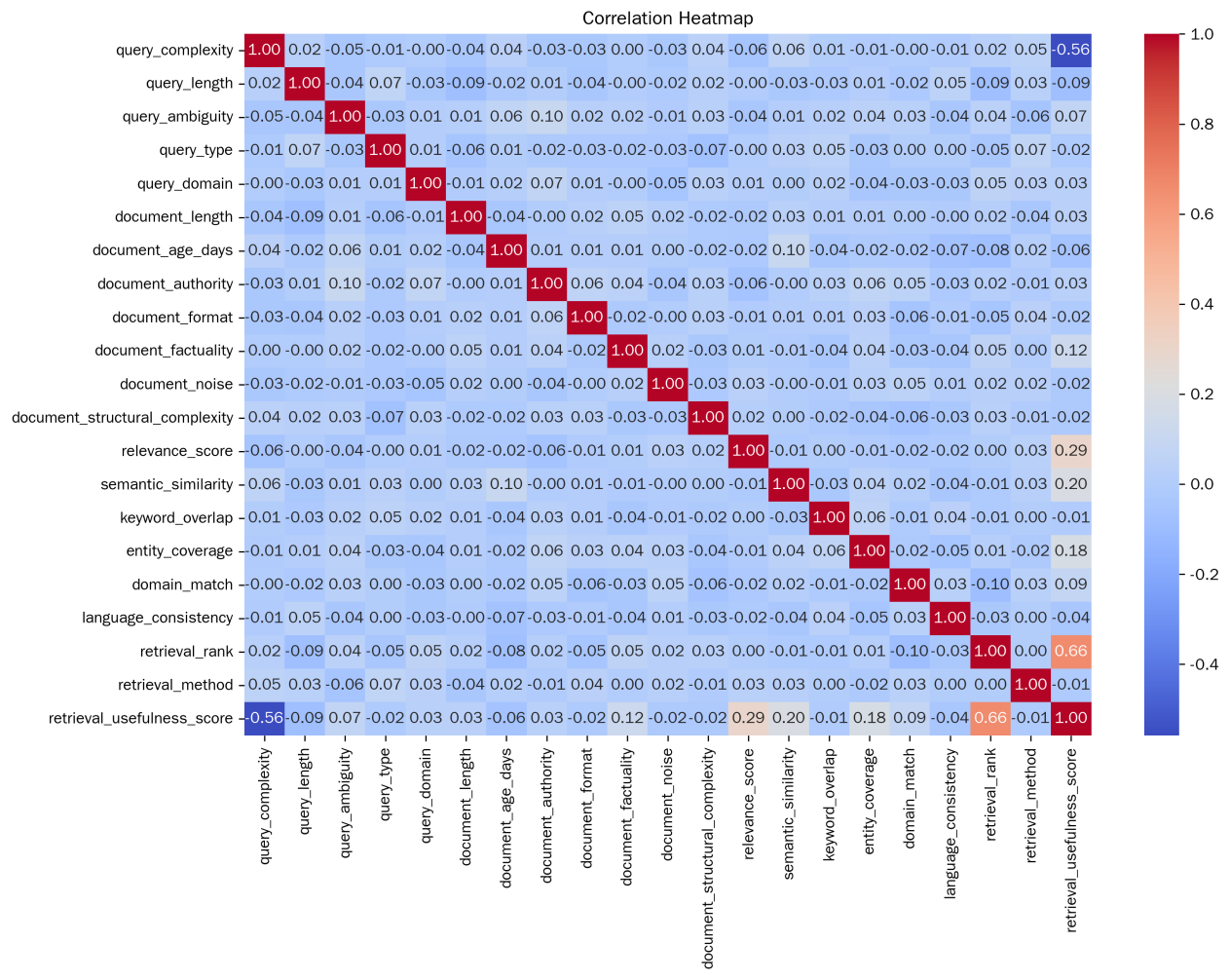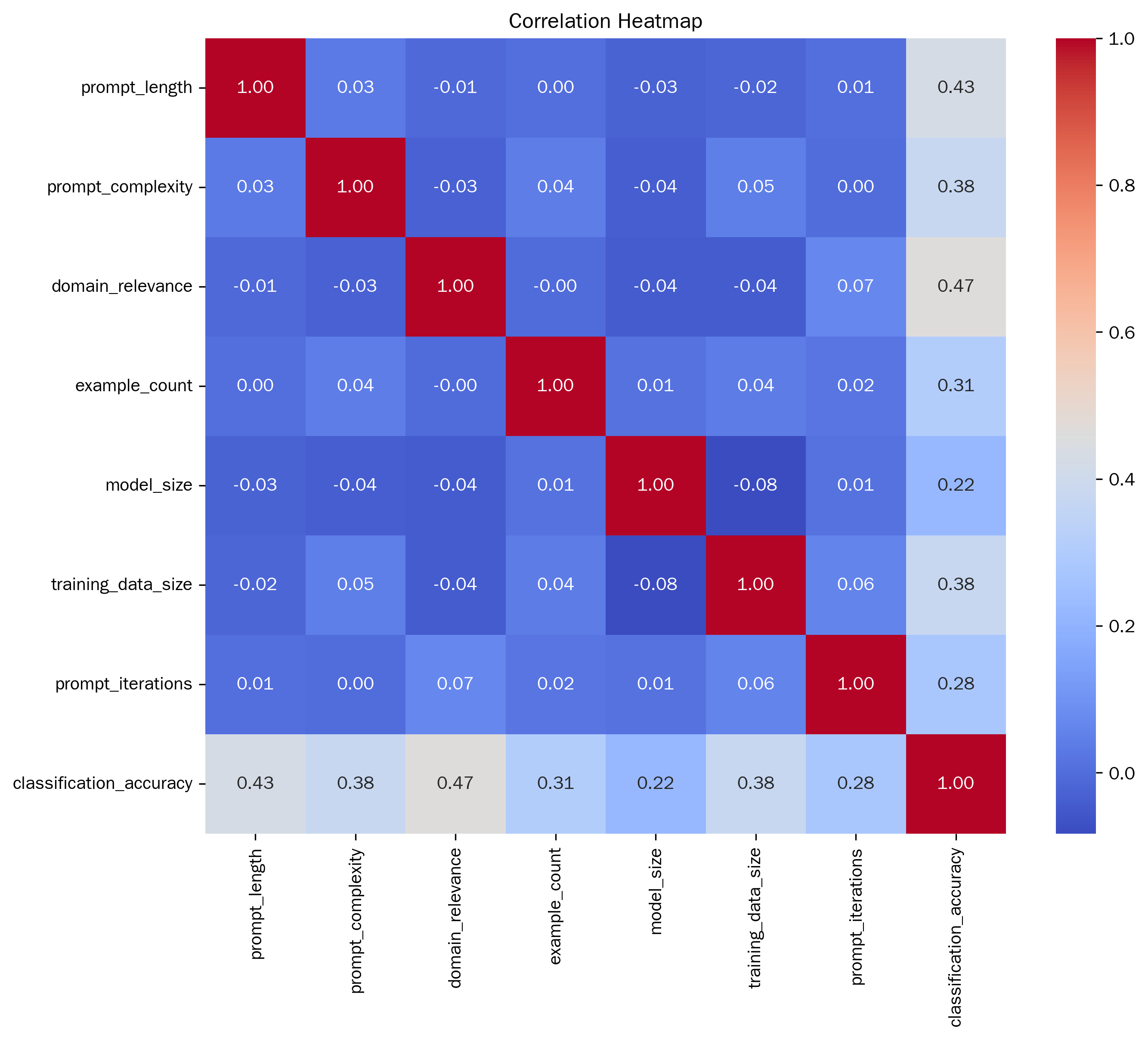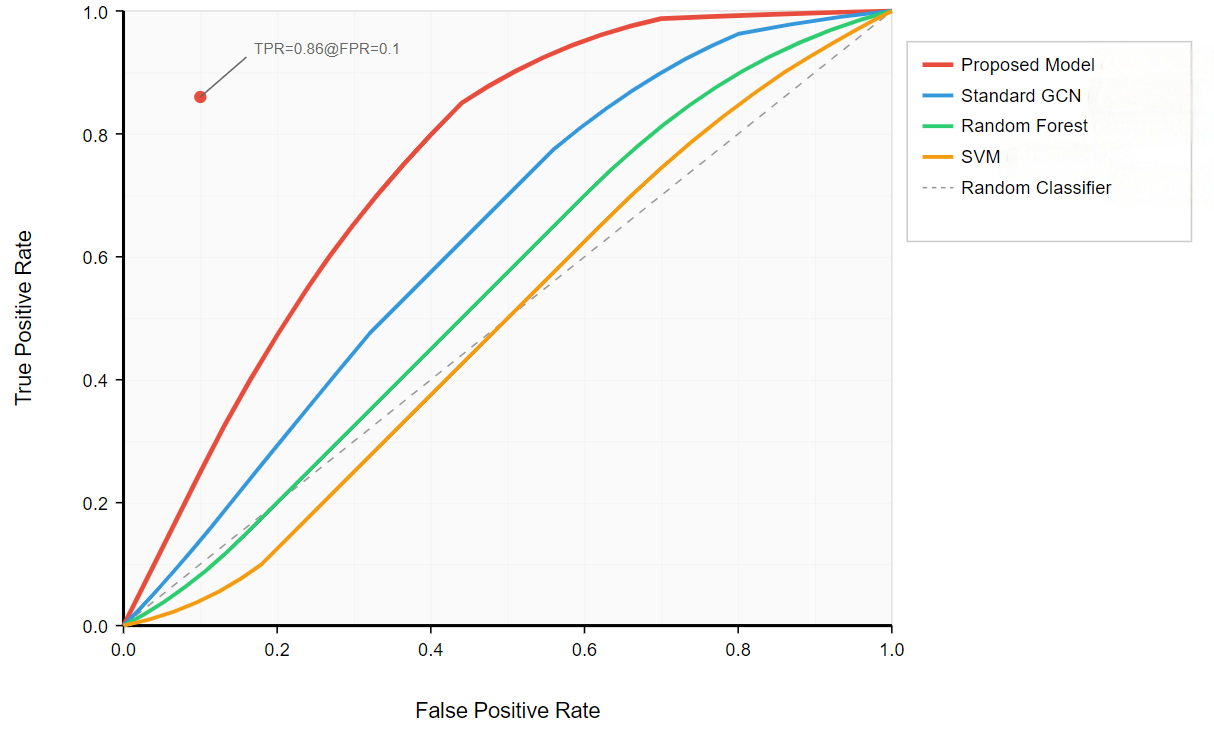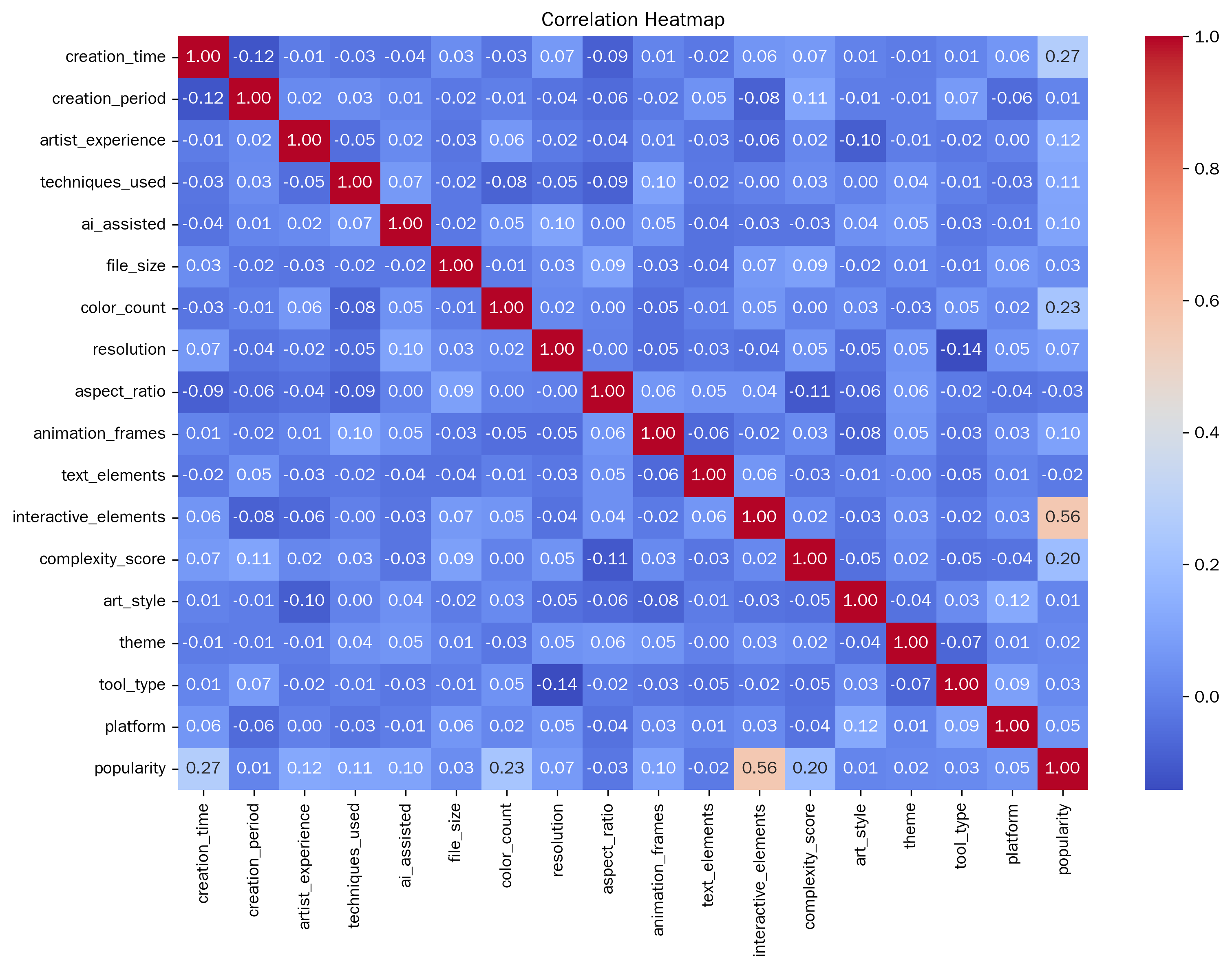
Exploring a quantitative evaluation system for the popularity of digital media art has become a core issue that connects artistic creation, technological application and market communication. In view of the bottlenecks existing in the current algorithms, this paper proposes an LSTM algorithm optimized based on the multi-head attention mechanism. The study first conducted a correlation analysis. The results showed that the number of interactive elements had the strongest correlation with popularity, with an absolute value of the correlation coefficient reaching 0.556887. Variables such as creation time, the number of colors, and complexity scores also have a certain correlation with popularity. It can be seen that the time invested in creation, the richness of colors, and the complexity of the work will, to a certain extent, affect the popularity of the work. Taking decision tree, random forest, CatBoost, AdaBoost and XGBoost as the comparative experimental objects, in terms of various indicators, Our model performed the best in Accuracy, Recall, Precision, F1 and AUC. Its Accuracy is 0.855, which is higher than that of decision trees (0.709), random forests (0.803), CatBoost (0.786), AdaBoost (0.778), and XGBoost (0.744), with the highest overall classification accuracy. The Recall and Precision were 0.855 and 0.856 respectively, also leading other models. It performed better in identifying positive samples and the proportion of actually positive samples among those predicted to be positive. The F1 value of 0.855 is also higher than that of other models, and it has a stronger ability to balance accuracy and recall. The AUC reached 0.904, surpassing the 0.875 of random forest and the 0.876 of CatBoost, demonstrating the best ability to distinguish between positive and negative samples. In comparison, other models are slightly inferior in various indicators, especially the overall performance of the decision tree and XGBoost, which is more significantly lower than that of the Our model. This research achievement provides a more efficient method for the quantitative assessment of the popularity of digital media art. It not only offers direction for the integration of artistic creation and technological application but also provides a scientific basis for the formulation of market communication strategies.