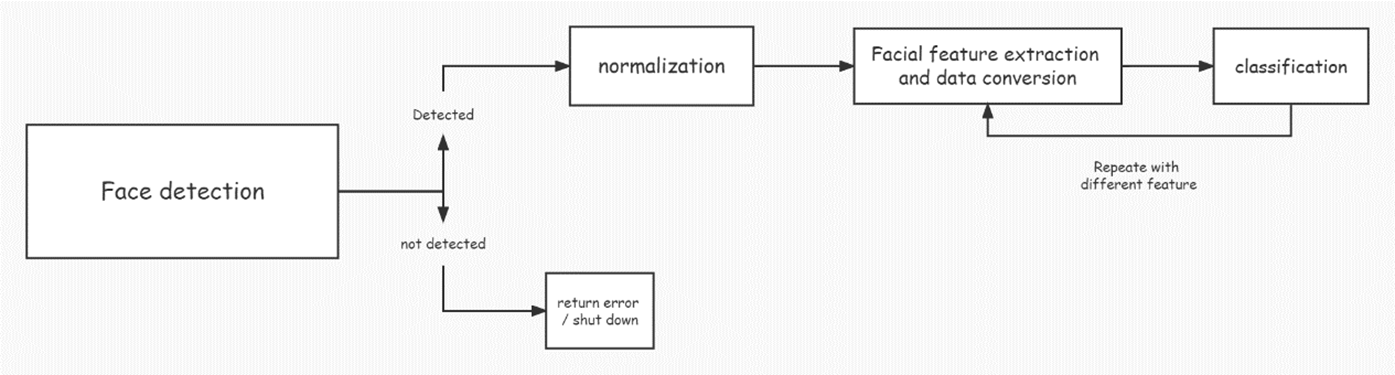
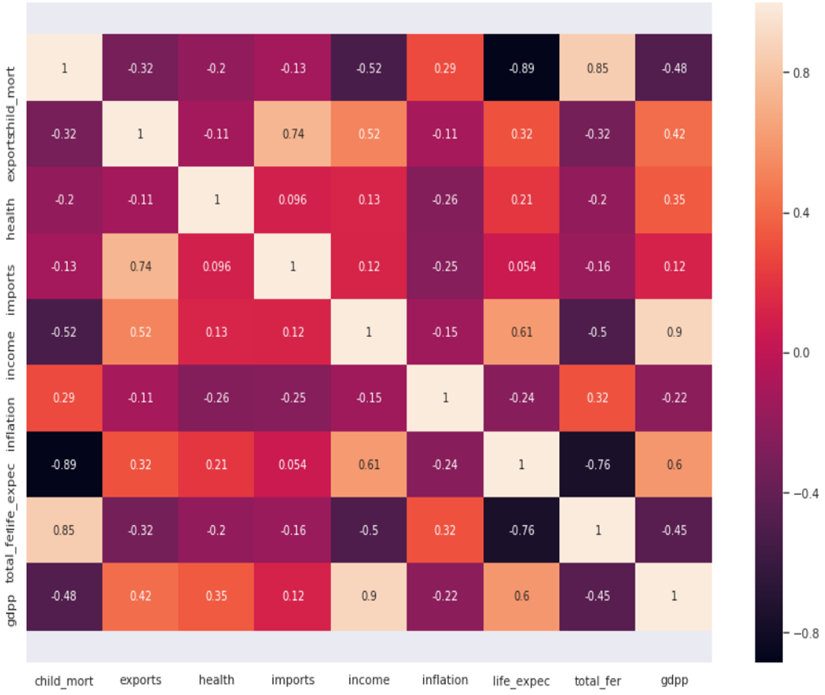
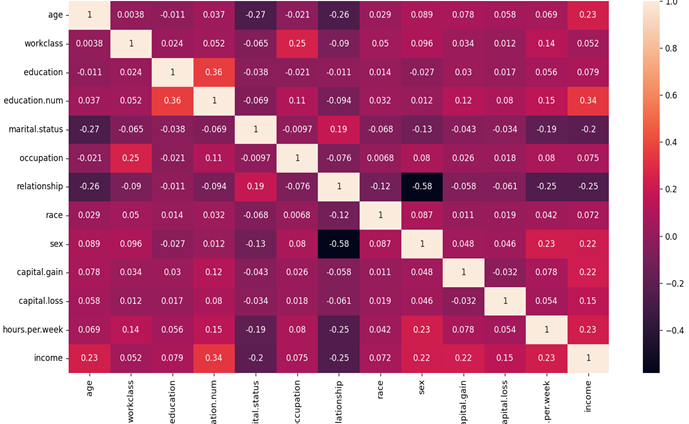
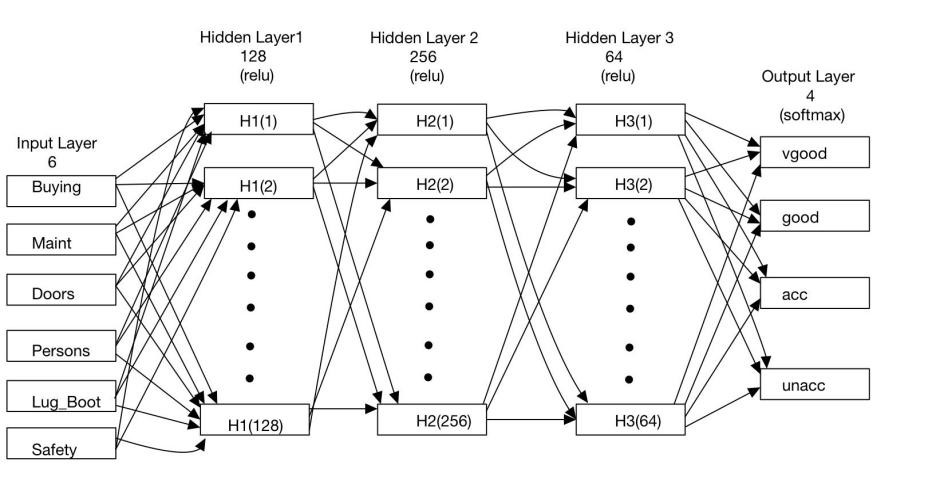
To be competitive in today's market, companies must constantly assess and improve their operations, and financial data analysis has emerged as a crucial tool for this purpose. Executives can utilize data analysis to gain a deeper understanding of the underlying facts in their data and make better informed decisions about their company and the market. Multiple data models in the language make it possible to have a fully functional language environment with tools for statistical analysis and visual visualization of data. With its ability to enhance the quality of work in statistical computations and graphical analysis, the R language is ideally suited to the industrial data analysis environment. In this paper, we use a literature review methodology to examine the domestic and international literature on R language big data visualization auditing, analyze the visualization application areas of R language big data auditing, discuss the benefits and challenges of big data auditing, demonstrate how R language can be adapted to real-world auditing scenarios, and offer reasonable recommendations and optimistic outlooks for the field's future.