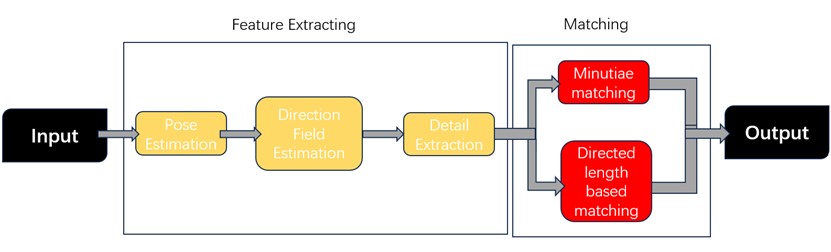
This paper presents a comprehensive exploration of the application of deep learning technology in fingerprint recognition, focusing on the development and impact of several novel algorithms. These algorithms have been specifically designed to address challenges in key sub-fields such as pose estimation, direction field estimation, minutiae extraction, and minutiae matching. By integrating deep learning techniques, these new approaches significantly enhance the accuracy, stability, and efficiency of fingerprint recognition systems. The study demonstrates that these algorithms surpass traditional methods in several critical areas, offering improved precision in recognizing fingerprints, particularly in high-noise environments. Furthermore, the fully differentiable nature of these models contributes to their robustness, enabling more consistent and reliable performance across diverse scenarios. The results underscore the potential for these deep learning-based algorithms to set new benchmarks in the field, with broad implications for their application in security, law enforcement, and other areas requiring reliable biometric authentication. The use of these cutting-edge methods is anticipated to be vital in influencing the direction of fingerprint recognition technology as it develops further, guaranteeing increased security and precision.