
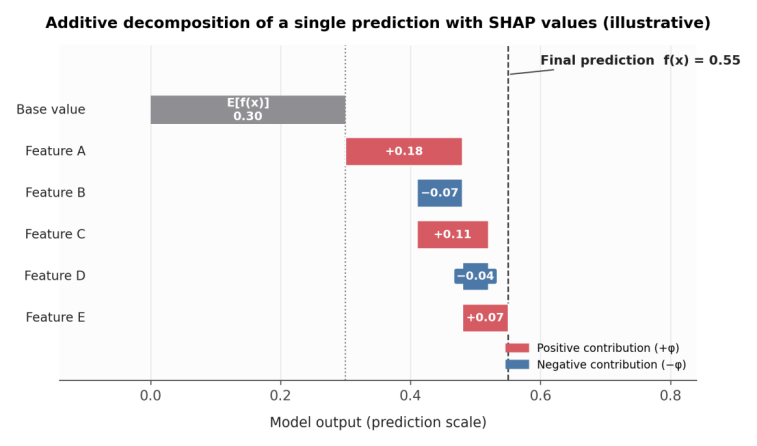
The rapid growth of big data and complex machine learning models—gradient-boosted trees and deep neural networks—has produced highly accurate but opaque"black-box"predictors across medicine, finance, and industry, making interpretability a central concern in data analysis. SHapley Additive exPlanations (SHAP), grounded in cooperative game theory, has become one of the most influential interpretability methods because it provides theoretically consistent feature attributions at both the local and global levels. This paper presents a systematic literature review of SHAP and its role in data analysis. It synthesizes SHAP's theoretical foundations, its main implementations (TreeSHAP, KernelSHAP, and DeepSHAP), its visualization toolkit, and its practical applications, and it reports a compact empirical study comparing the three explainers on a clinical dataset. This study finds that, although SHAP markedly improves transparency and decision support, open challenges remain in computational cost, the reliability of explanations under feature correlation, and consistency across methods. The significance of this work is twofold: theoretically, it organizes SHAP's variants and properties within a single coherent framework; practically, it offers data analysts a structured, evidence-based reference for selecting and applying SHAP appropriately, thereby supporting more transparent, reliable, and accountable model-driven decisions.