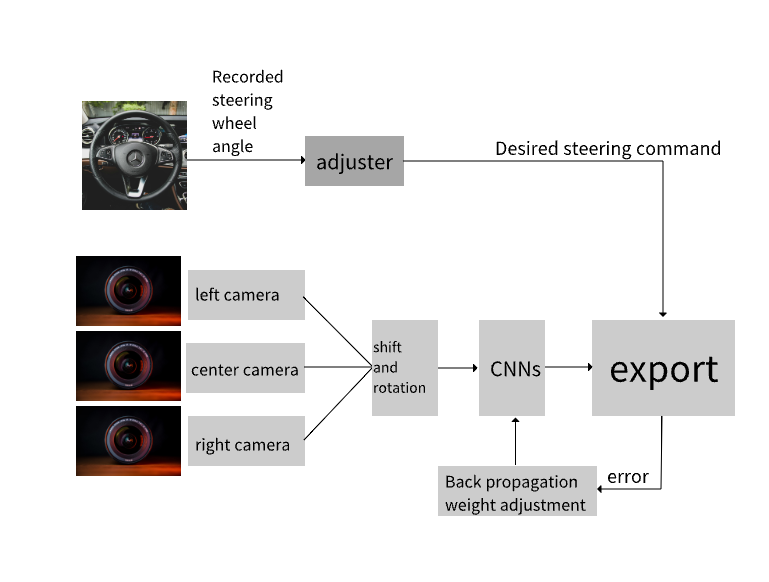
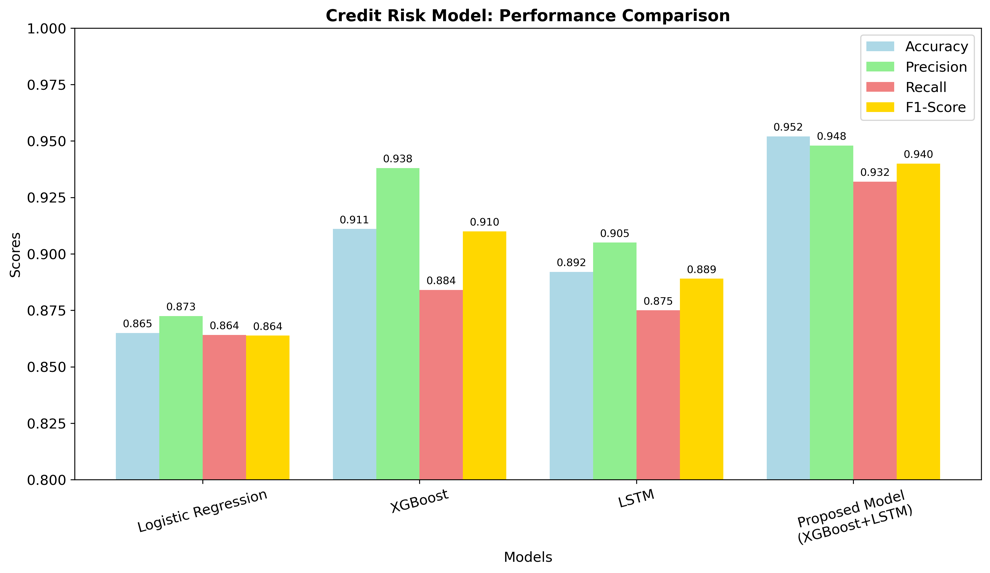
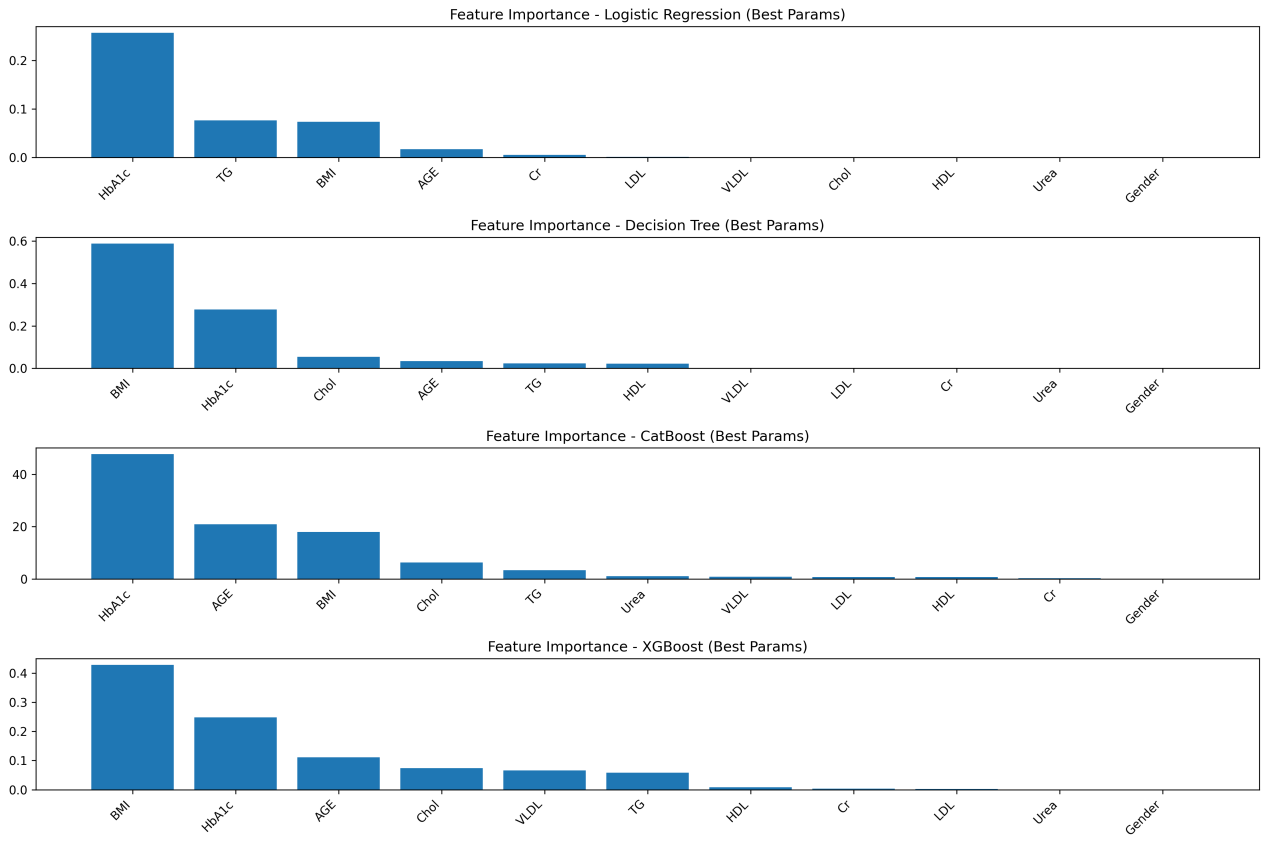
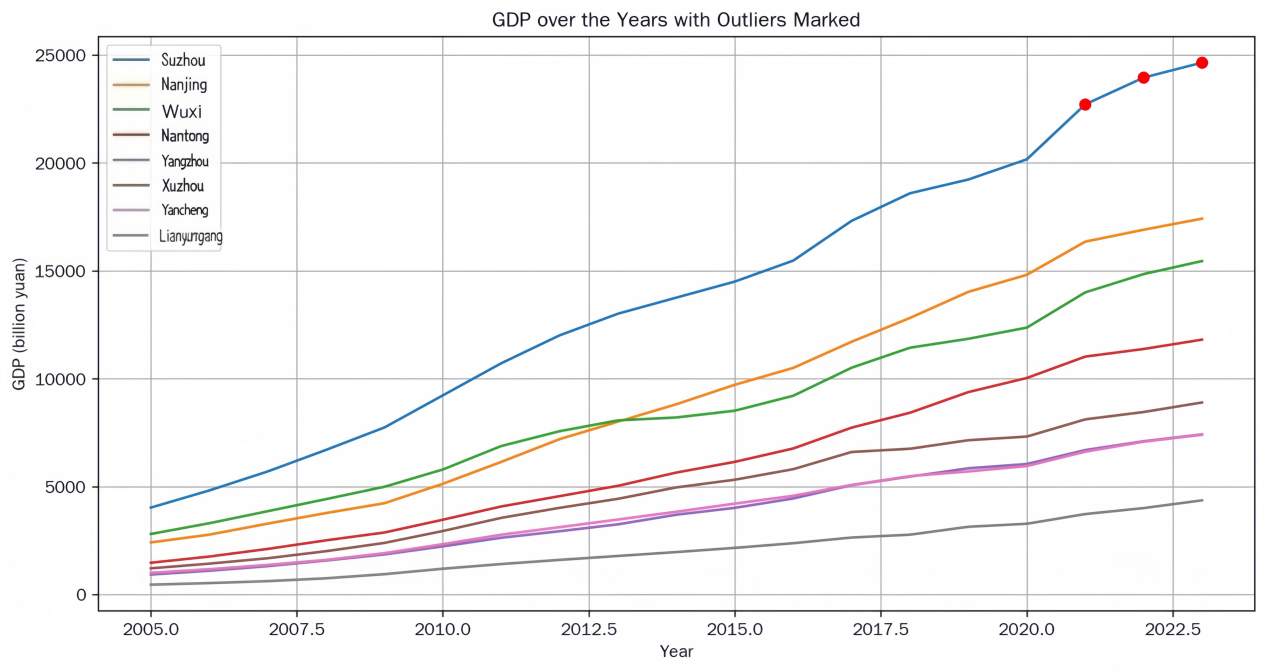
Deep learning has advanced image recognition, achieving strong results in medical imaging, autonomous driving, and security. Yet significant bottlenecks still limit deployment. This paper reviews three main challenges: weak robustness, high computational demands, and reliance on large labeled datasets. Recent studies identify the causes of these issues, including growing model complexity, distribution shifts between training and real data, and lack of security-aware design. To address these problems, various strategies have been developed in the past five years. For robustness, adversarial training, data augmentation, and domain adaptation have been widely applied. To enhance the efficiency of deep learning models, techniques including network pruning, parameter quantization, and lightweight architectures (e.g., MobileNet and EfficientNet) are widely adopted—often augmented by knowledge distillation and hardware-aware neural architecture search (NAS). To mitigate reliance on large-scale labeled datasets, approaches such as transfer learning, self-supervised learning frameworks (e.g., SimCLR and BYOL), and multimodal models (e.g., CLIP) have demonstrated promising performance. While progress is evident, trade-offs remain. Future work should focus on combining these strategies to achieve models that are simultaneously accurate, efficient, and robust for real-world applications.
Research Article
Open Access